This post is based on notes from reading Controlled experiments on the web: survey and practical guide by Ron Kohavi, Roger Longbotham, Dan Sommerfield, and Randal M. Henne. Read part 1 here.
MultiVariable Testing
Multivariable testing (MVT): an experiment that includes more than one factor (experimental variable). e.g. treatment variant has more than one changes compared to the control variant. With this single test, we can estimate the (main) effects of each factor and the interactive effects between factors.

Benefits of a single MVT vs. multiple sequential A/B tests to test the same factors:
- Test many factors in a short period of time, accelerating improvement.
- You can estimate the interaction between two factors. Two factors have an interaction effect if their combined effects are different from the sum of two individual effects.
Limitations:
- Some combination of factors may give a poor user experience.
- Analysis and interpretation are more difficult.
- It can take longer to begin the test.
The limitations are not serious in most cases to deter one from conducting MVT. It is preferable to have your first experiment as an A/B test due to the complexity of testing more than one factor in the same test.
3 Approaches to Conducting MVT
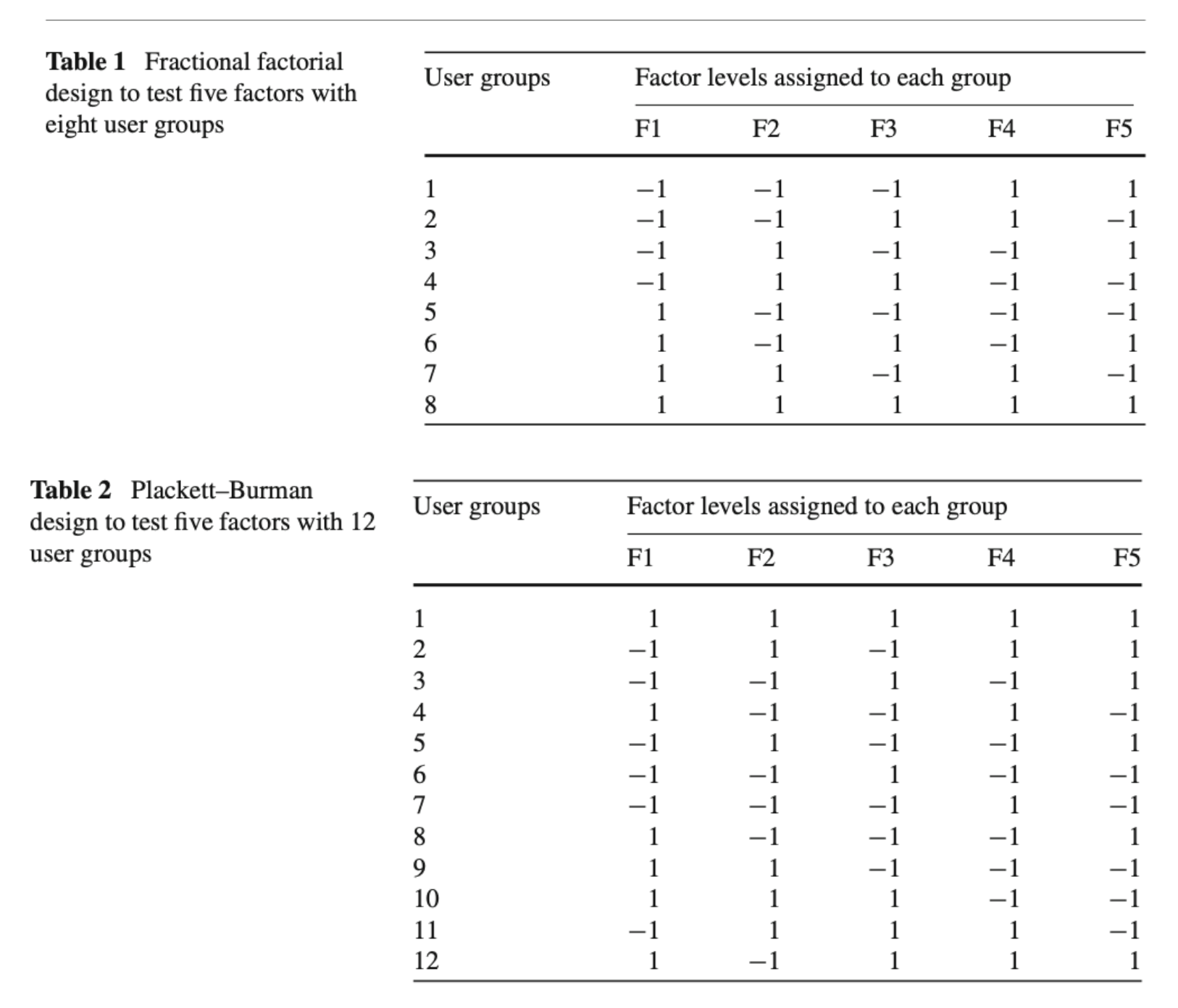
- Traditional MVT - fractional factorial/Plackett and Burman (Taguchi)
Full factorial has all combinations of the factors which would be 2^5=32 user groups. A fractional factorial is a fraction of the full factorial.
The fractional design in table 1 (-1: control, 1: treatment) can estimate the 5 main effects but not the interactions well. But for many, the primary reason for running MVT is to estimate interactions among factors being tested. This approach is not recommended for this purpose compared to the two other approaches below.
2. MVT but running concurrent tests
We can set up each factor to run as a one-factor experiment and run all these tests concurrently and get a full factorial in the end. We can start and stop all these one-factor tests at the same time on the same set of users with users being independently randomly assigned to each experiment, and you will get a full factorial.
The benefit of this approach:
- You can estimate any interactions you want with a full factorial (ANOVA test)
- You can turn off any factors at any time if any factors is disastrous without affecting the other factors.
Examples from optimizely on this which is essentially a full factorial test.
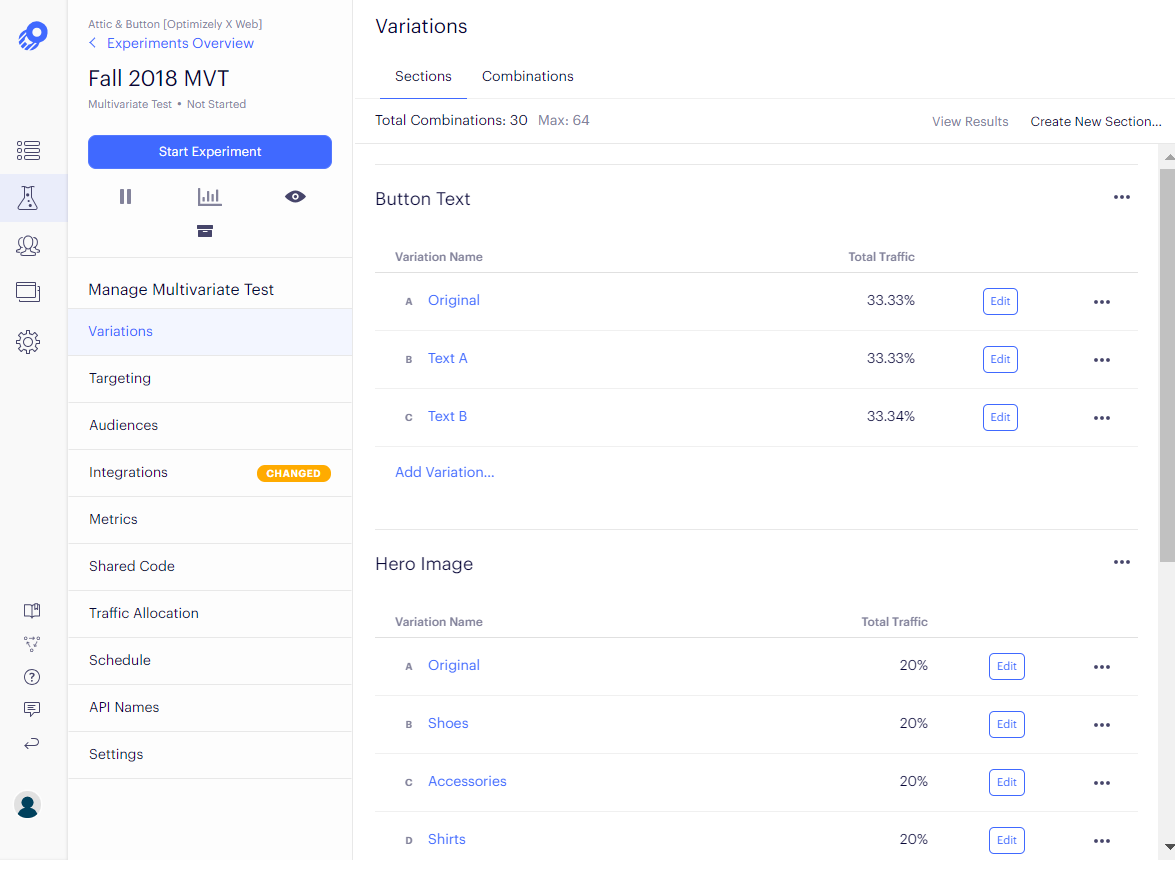
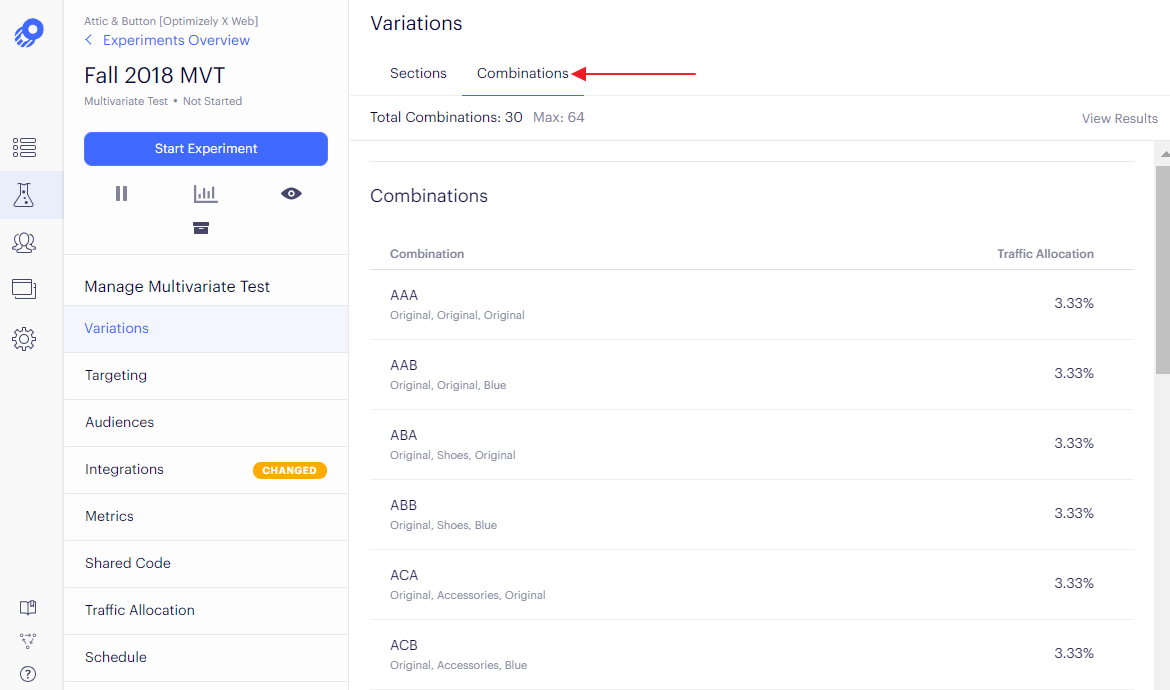
If you compare each individual cell to the control cell, the power of the experiment will decrease with the number of treatment combinations. But if the analysis is calculating mean effects and interaction using all the data for each effect, little or no power is lost.
A loss of power could occur if one combination of factors increase the variance of the response. Using a pooled estimate for experimental error will minimize any loss of power.
Two things that will reduce your power:
- increasing the number of levels (variants) for a factor
- unbalanced population between treatments and control.
3. Overlapping experiments
If you want to maximize the speed with which ideas are tested (significant benefits to running more tests more frequently as they are ready to be deployed) and you are not interested in or concerned with interaction effects*, you can simply test a factor as a one-factor experiment when the factor is ready to be tested with each test being independently randomized.
*Large interactions between factors are rarer than most people believe unless they are already known. In this case, you can test those factors at the same time and can estimate interactions.
Implementation architecture
Implementing an experiment on a website involves three components
- randomization algorithm
- assignment method
- data path
Randomization algorithms
a function that maps end-users to variants. Randomization algorithms must have the following three properties to support statistically correct experiments:
- end-users must be equally likely to see each variant of an experiment
- repeat assignment of a single end-user must be consistent, the end-user should be assigned to the same variant on each successive visit to the site (concern w/ cross-device tracking, incognito visits)
- when multiple experiments are run, no correlation between experiments user assignment. An end users's assignment to a variant in one experiment must have no effect of the probability of being assigned to a variant in any other experiment
optional but desirable properties:
- support monotonic ramp-up: percentage of users who see a treatment can be slowly increased without changing the assignments of users who were previously assigned to that treatment. Treatment percentage can be slowly increased without impacting the user experience or damaging the validity of the experiment.
- support external control, meaning that users can be manually forced into and out of variants.
Type of randomization techniques that fit the must-have requirements:
- Pseudorandom with caching
A standard pseudorandom number generator can be used as a randomization algorithm coupled with a form of caching. Random number generators work well as long as the generator is seeded only once at server startup. Seeding the random number generator on each request may cause adjacent requests to use the same seed which may introduce noticeable correlations between experiments. To satisfy the 2nd requirement, the assignments of end-users must be cached once they visit the site (on the server-side by storing assignment of users in a database (can get expensive quickly) on the client-side - store user assignment in a cookie (will not work with users with cookies turned off)).
2. Hash and partition
A good hash function produces randomly distributed numbers as a function of input: each user is assigned a single unique identifier (maintained through a database or a cookie) and each experiment is assigned a unique identifier. A hash function is applied to the combination of the user identifier and experiment identifier (e.g. by concatenating them together) to obtain an integer that is uniformly distributed on a range of values. The range is then partitioned with each variant represented by a partition. Optimizely uses this method for user bucketing. Read more here.
Assignment method
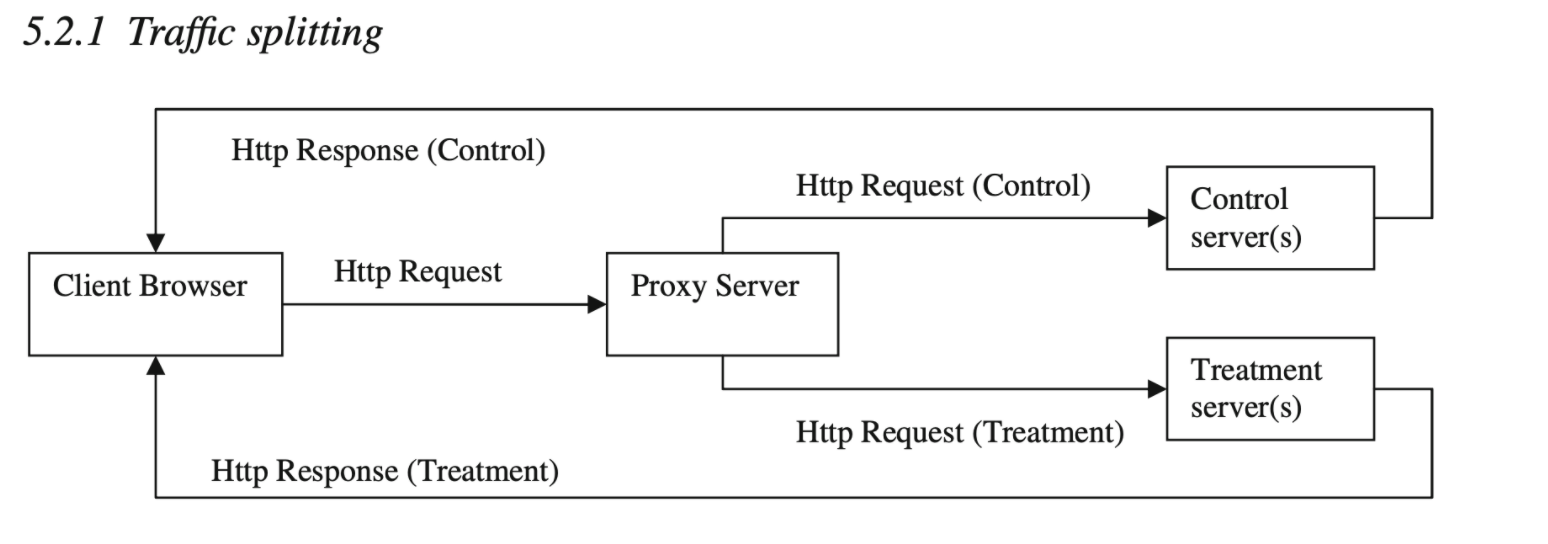
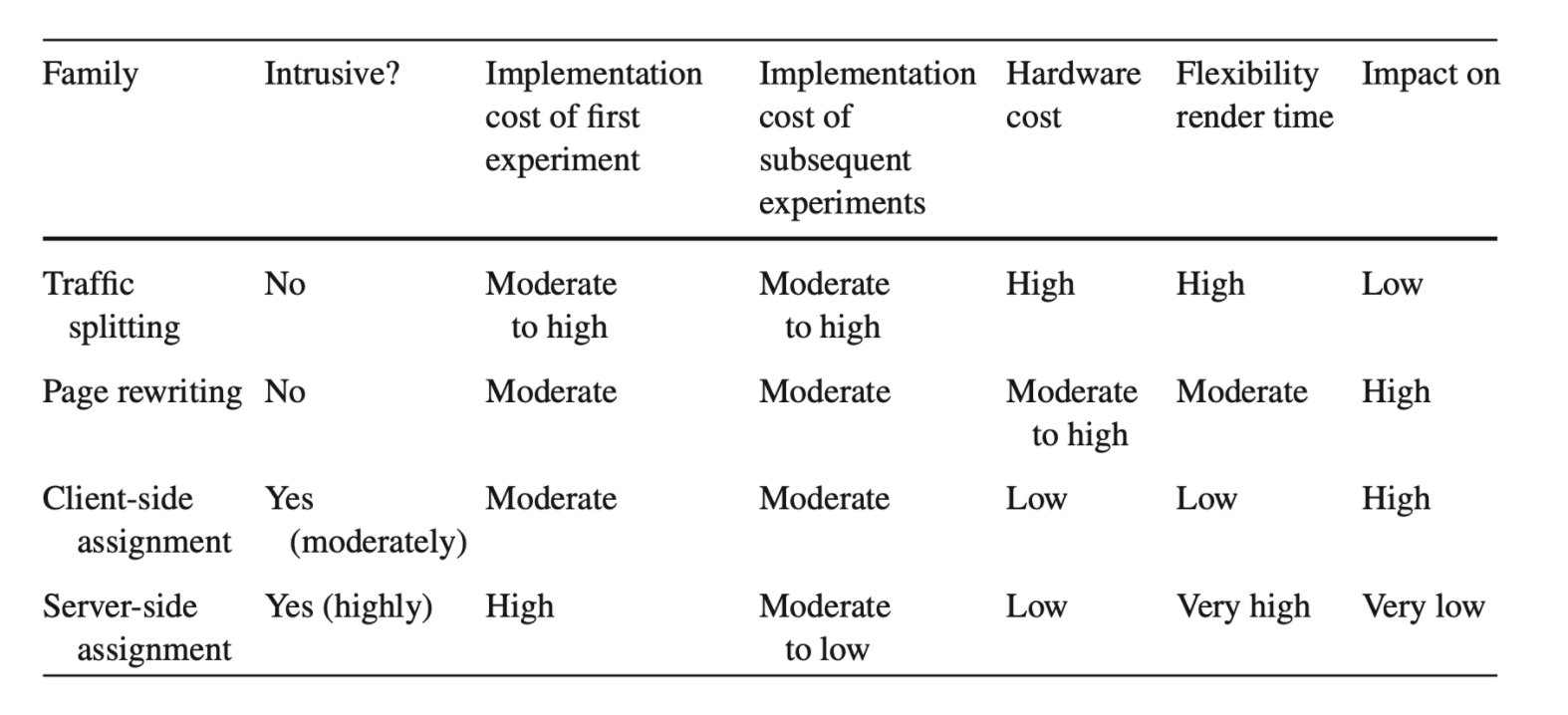
- Traffic splitting
This method refers to implementing each variant of an experiment on a different logical fleet of servers. It is recommended for testing changes that introduce significantly different code, such as migration to a new website platform, or a complete upgrade of a site.
2. Page rewriting
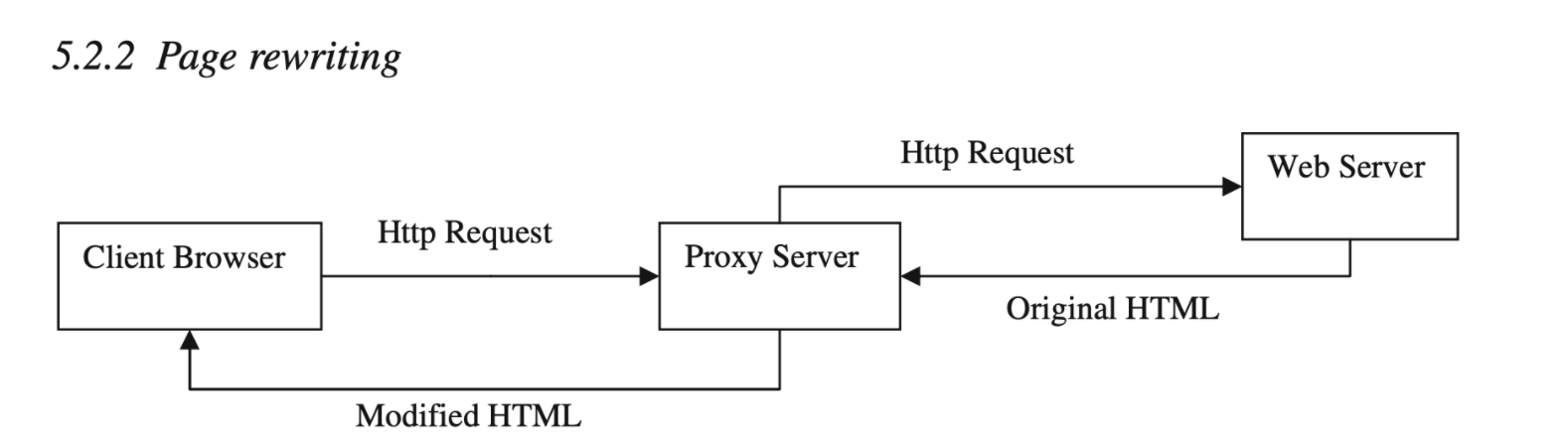
This method modifies HTML content before it is presented to the end-user. Disadvantages with this method are:(i) page render time (ii) development and testing are difficult and error-prone.
3. Client-side assignment
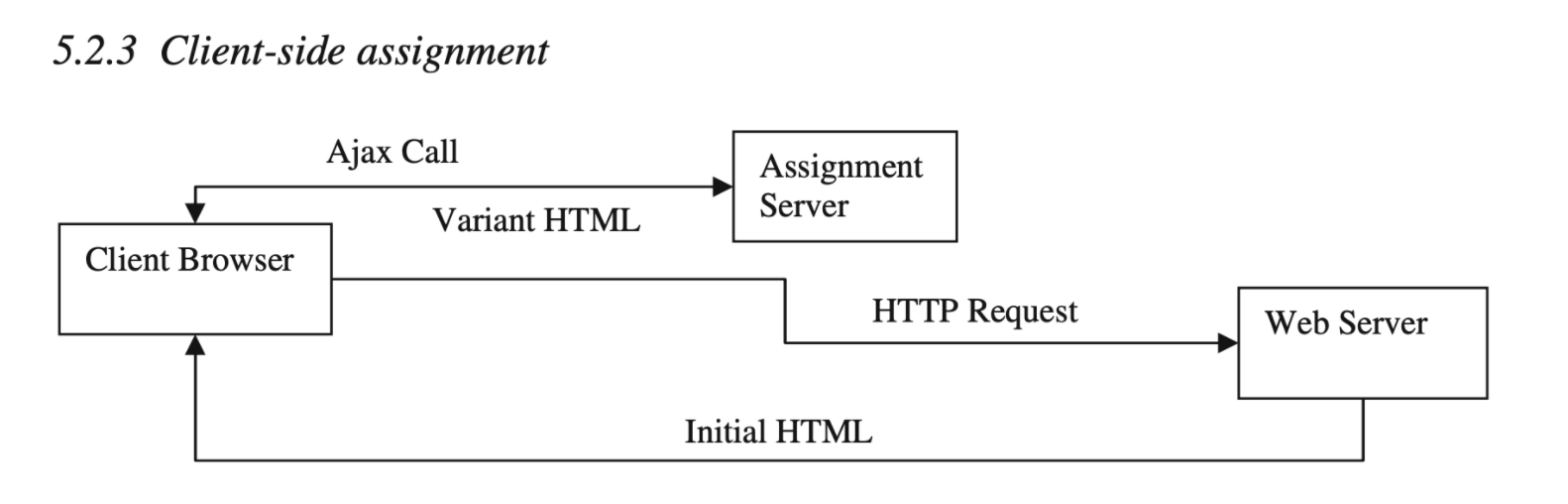
This is the most popular assignment method in third-party experimentation platforms. A developer implements an experiment by inserting JavaScript code that instructs the end user's browser to invoke an assignment at render time. The service call returns the variant for the end-user and triggers a JS callback that instructs the browser to dynamically alter the page presented to the user, by modifying the DOM. The limitation with this method: the assignment executes after the initial page is served and delays the end-user experience; the method is difficult to employ on complex sites with dynamic content so it's best for experiments on front-end content that is primarily static.
4. Server-side assignment
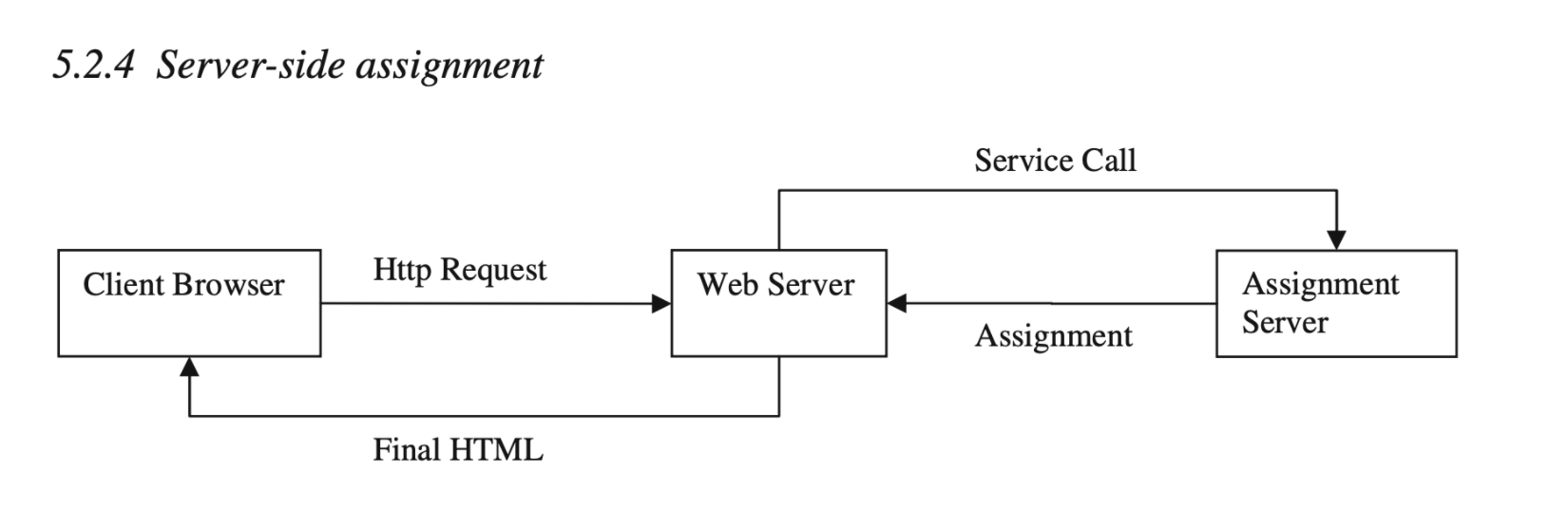
Server-side assignments use code embedded to the website's server to produce different experiences, like performing API calls. A complex experiment may make uses of multiple API calls inserted into code at different places. Advantages of the server-side assignment are: minimal delay and interruption for user experience; possible to experiment on backend features like personalization algorithms without touching the front end; general method can make it possible to experiment on any aspect of a page. The disadvantages mainly stem from the intrusiveness of the method that makes it expensive and difficult to implement (heavy dependency on programmers).
Server-side assignment can be integrated into a content management system to reduce the cost of running experiments using this method. Experiments are configured by changing metadata instead of code. Metadata can be anything from
Example from Amazon:
- Amazon's home page is built on a content management system that assembles page from individual units - slots.
- The system refers to page metadata at render time to determine how to assemble the page
- Non-technical content editors schedule pieces of content in each slot through a UI that allows user to edit this page metadata and with respect to a specific experiment.
- As page request comes in, the system executes the assignment logic for each scheduled experiment and saves the results to page context where page assembly mechanism can react to it.
- The content management system only needs to be modified once and experiments can be designed, implemented, and removed by modifying the page metadata through the UI.
Summary of relative advantages and disadvantages of different assignment methods
Data Path
To compare metrics across experiment variants, a site must record treatment assignment, page view, clicks, revenue, user identifier, variant identifier, experiment identifier, etc. Site experimentation raises some specific data issues
- Event-triggered filtering
With high variability of data collected from web traffic, it is difficult to run an experiment with sufficient power to detect effects on small features. One way to control this variability is the restrict the analysis to users who were impacted by the experiment, and further restrict the analysis to the portion of user behavior that was affected by the experiment. This data restriction is called event-trigger filtering. This is implemented by tracking the time at which each user first saw content affected by the experiment - can be collected directly by recording an event when a user sees experimental content (a flag) or indirectly (identifying experimental content from raw data).
2. Raw data collection
- using existing data collection - not set up statistical analysis so require manual and require frequent change of code to accommodate for new experiments
- local data collection
- server-based collection: service call to centralize all observation data and make it easy for analysis. This is the preferred method when possible.
Practical Lessons Learned
Analysis
- Mine the data. An experiment provides rich data, more than just a bit about whether the difference in OEC is to stay sig. E.g. An experiment showed no significant difference overall, but a population of users with a specific browser version was significantly worse for the treatment, then revealed that the treatment JS was buggy for that browser version.
2. Speed matters. A treatment might provide a worse user experience because of its performance (speed), experiments at Amazon showed a 1% sales decrease for an additional 100msec. If time is not directly part of your OEC, make sure a new feature that is losing is not losing because it is slower.
3. Test one factor at a time (or not):
- do single-factor experiments for gaining invites and when you make incremental changes that could be decoupled
- try some bold bets and very different designs and you might then perturb the winning version to improve it further
- use full or fractional factorial designs for estimating interaction when several factors are suspected to interact strongly
Trust and execution
- Run continuous A/A tests to validate the following in parallel with other experiments:
- Are users splitting according to the planned percentages
- Is data collected matching the system of record
- Are results showing non-significant results 95% of the time
2. Automate ramp-up and abort:
- It is recommended to gradually increase the percentage of users assigned to treatment(s)
- Then an experimentation system that analyses the experiment data in near-real-time can automatically shut down a treatment if it's significantly underperforming relative to the control
- An auto-abort reduces the percentage of users assigned to underperforming treatment to zero. Then you can make bold bets and innovate faster.
3. Determine the minimum sample size:
- Decide on the statistical power, the effect you would like to detect, and estimate the variability of the OEC through an A/A test. You can compute the minimum sample size needed and run time for your website
- A common mistake is to run experiments that are underpowered.
4. Assign 50% of users to treatment:
- Instead of doing 99% vs. 1% split worrying that treatment would affect too many users, we recommend treatment ramp-up and maintaining a 50-50 test split.
- The test would need to be run longer with an unbalanced split. An approximation for the increase in run time for an A/B test relative to a 50-50 split is 1/(4p(1-p)) where treatment receives a portion p of the traffic. A 99%/1% split would run 25 times longer compared to a 50%/50% test.
5. Day of the week effect:
Experiments should be run at least a week or two so day-of-week effects can be analyzed. The segment visiting on the week representing different segments and analyzing them might lead to interesting insights.
Culture and Business
- Agree on the OEC upfront
An evaluation of many online features may be subject to several and often competing objectives, a good technique is to assess the lifetime value of user and their actions. Aligning to an OEC before the experiment can help clarify goals.
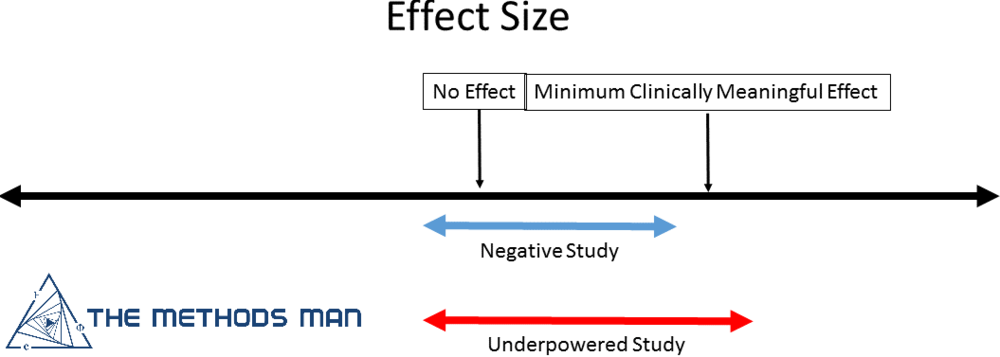
2. Be aware of launching features that "do not hurt" users
In the face of a no significant different result, sometimes the decision is to launch the change anyway "because it does not hurt anything" . But it is possible that the experiment is negative but underpowered.
3. Weigh the feature maintenance costs
You might not want to launch a feature if the upside of OEC is overshadowed by the feature maintenance cost.
If you are interested in learning more about a/b/n testing, I highly recommend the book Trustworthy Online Controlled Experiments (A Practical Guide to A/B Testing) .