
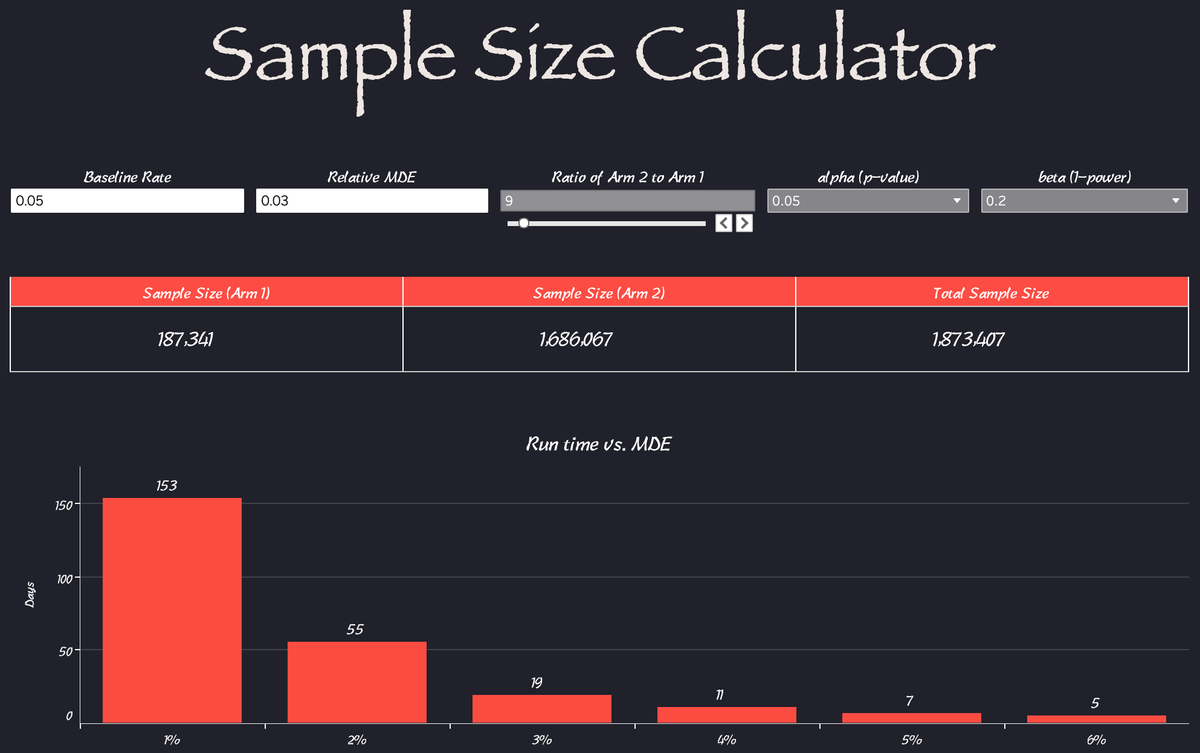

If you work in teams that do experimentations, you must have heard the term ‘size the test’, that is to estimate the sample size needed for a test. Why size a test before it starts? So:
- You don’t finish a test with a sample size that cannot detect the effect you want to detect to make a business decision
- You have a stopping point -you don’t end the test through p-hacking
- You can prioritize and plan tests with the limited amount of traffic you’ve got
It’s surprisingly hard to find an online sample size calculator that has all the components needed for calculating sample size. So I put together one for proportion metrics (conversion rate, click-through rate), as always, for you and for me.
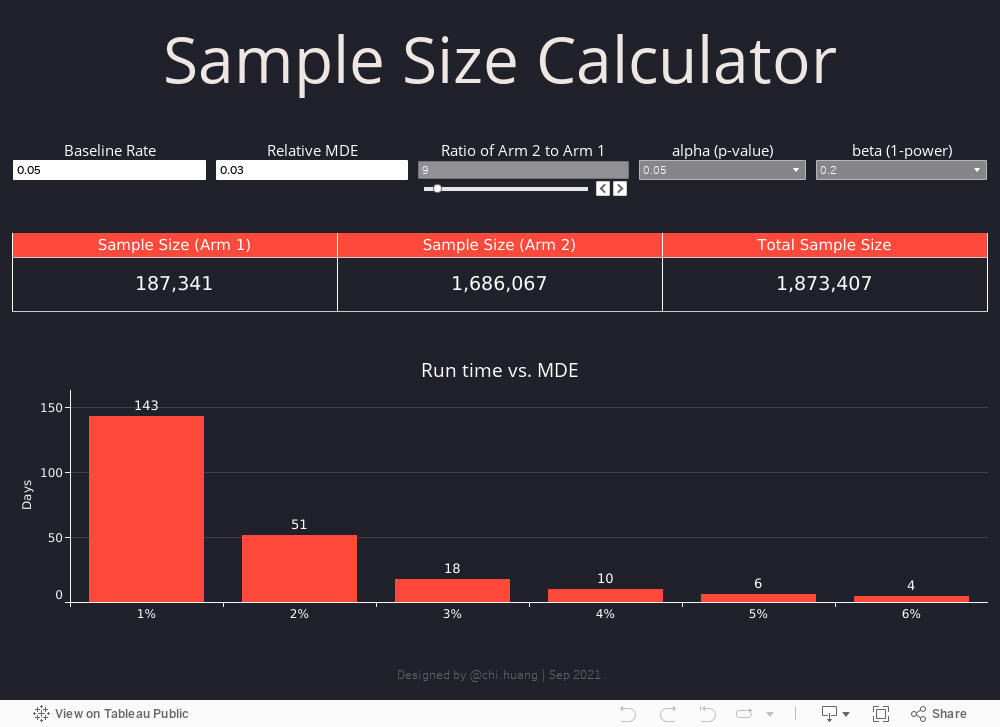
Components of this sample size calculator:
- Baseline rate: the higher the baseline rate, the less sample size is needed to detect a certain MDE.
- Relative MDE: the minimal detectable effect relative to the baseline rate the given sample size can detect. MDE indicates practical significance, what’s the lift that’s needed to make a business decision. 1% increase in conversion rate for Amazon has much higher practical significance than a 1% increase in conversion rate for an early-stage start-up.
- Ratio of arm 2 to arm 1: not every test is 50–50 split, if you need to create a global holdout group it usually is 1% — 10% of the total sample.
- P-value: the probability of detecting the observed difference or more extreme under the assumption there is no difference.
- Power: the probability of not committing a type-II error — the ability to detect a difference if there’s one.
- Runtime vs. MDE: when making sample size recommendations, it’s always helpful to think as your stakeholder. What do they care about? How long do we need to run the test to detect a difference that we want to detect?
If you want to customize one for yourself, you can download the template here.
P.S. If you are interested in learning more, here are some books on experimentations that helped me with my job & interviews that I highly recommend.
Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing: 9781108724265: Computer Science Books @ Amazon.com
Trustworthy Online Controlled Experiments: A Practical Guide to A/B Testing: 9781108724265: Computer Science Books @ Amazon.com

Amazon.com: The Essential Guide to Effect Sizes: Statistical Power, Meta-Analysis, and the Interpretation of Research Results: 9780521142465: Ellis, Paul D.: Books
Amazon.com: The Essential Guide to Effect Sizes: Statistical Power, Meta-Analysis, and the Interpretation of Research Results: 9780521142465: Ellis, Paul D.: Books

![Sample Size Calculator [Tableau Workbook]](https://storage.ghost.io/c/86/ef/86ef37c4-a2ea-4141-8365-88fa6bf16ba7/content/images/size/w300/2021/09/samplesizecalculator.png)
![Outlier Detection with Tableau [Tableau Workbook + Data]](https://storage.ghost.io/c/86/ef/86ef37c4-a2ea-4141-8365-88fa6bf16ba7/content/images/size/w300/2021/05/Dashboard-1--15--2.png)